Download præsentationen
Præsentation er lastning. Vent venligst

1
Økonometri – lektion 6 Multipel Lineær Regression
Kategoriske forklarende variable Polynomiel regression Ikke-lineære modeller

2
Multipel lineær regression og kvalitative forklarende variable
Eksempel Y = Vægt i kg R (kontinuert. afh. var.) XHøjde = Højde i cm R (kont. forkl. var.) XKøn = Køn {Mand,Kvind} (kval. forkla. var.) MLR Model (generelt) Hvordan får vi passet Xkøn ind her?
 XHøjde = Højde i cm R (kont. forkl. var.) XKøn = Køn {Mand,Kvind} (kval. forkla. var.) MLR Model (generelt) Hvordan får vi passet Xkøn ind her")
3
Omkodning at kvalitativ variabel
Omkod Xkøn til binær variabel XKvinde Xkvinde = 1 hvis XKøn = Kvinde Xkvinde = 0 hvis XKøn = Mand Model

4
Fortolkning af model Når XKøn = Mand Når XKøn = Kvinde
To linjer med forskellig skæringspunter! Kvinde angiver forskellen i skæringspunkt.

5
To regressions linjer med forskellige skæringer, men samme hældning
Y Linje for XKvinde=1 β0 + βKvinde Linje for XKvinde=0 β0 X1

6
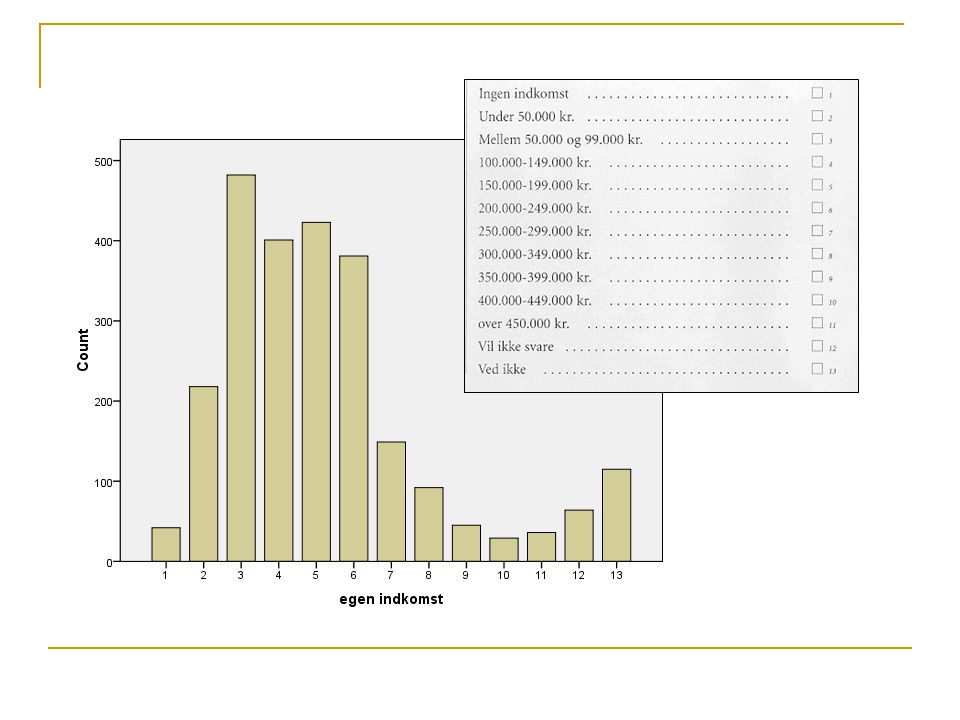
Omkodning i SPSS I det konkrete data er køn lagret i variablen ’kon’ som tager værdierne 1 og 2. Da vi skal bruge variabel med værdierne 0 og 1 skaber vi en ny variabel kon2=kon-1. I SPPS anvendes Transform→Compute...

7
Regressionslinje for mænd:
Regressionslinje for kvinder:

8
Mere end to kategorier Eksempel
Y = Vægt i kg R (kontinuert. afh. var.) XHøjde = Højde i cm R (kont. forkl. var.) XLøn = Løn {Lav,Mellem,Høj} (kval. forkla. var.) XLøn har tre kategorier XLøn omkodes til to binære variable
 XHøjde = Højde i cm R (kont. forkl. var.) XLøn = Løn {Lav,Mellem,Høj} (kval. forkla. var.) XLøn har tre kategorier. XLøn omkodes til to binære variable.")
9
Omkodning at kvalitativ variabel
XLøn omkodes til to binære variable XMellem og XHøj: XMellem = 1 hvis XLøn = Mellem XMellem = 0 hvis XLøn ≠ Mellem XHøj = 1 hvis XLøn = Høj XHøj = 0 hvis XLøn ≠ Høj Som tabel XLøn XMellem XHøj Lav Mellem 1 Høj

10
Fortolkning af model Model: Når XLøn = Lav : Når XLøn = Mellem :
Når XLøn = Høj : Tre linjer med forskellig skæringspunter!

11
Fortolkning af model Fortolkning af model
Forskellen i gennemsnitsvægt for to personer med samme højde, men fra hhv. løngruppe ’Mellem’ og ’Lav’. Vi siger at ’Lav’ kategorien er reference-kategori.

12
Kvalitative Variable og Test
Uinteressant hypotesetest (hvorfor?) H0: bMellem = 0 vs H1: bMellem ≠ 0 Interessant hypotesetest (hvorfor?) H0: bMellem = bHøj = 0 H1: bMellem ≠ 0 og/eller bHøj ≠ 0
 H0: bMellem = 0 vs H1: bMellem ≠ 0. Interessant hypotesetest (hvorfor ) H0: bMellem = bHøj = 0. H1: bMellem ≠ 0 og/eller bHøj ≠ 0.")
13
Hypotesetest H0: bMellem = bHøj = 0 H1: bMellem ≠ 0 og/eller bHøj ≠ 0
SSE: Sum of squared errors for regression, hvor bMellem og bHøj er med. SSE*: Sum of squared errors for regression, hvor bMellem og bHøj ikke er med. Teststørrelse: q: Antal parametre involveret i H0 k: Total antal regressions parametre i modellen

14
Y b0+bHøj b0+bMellem b0 XHøjde

15
Dummy-variable Generelt omkodes en kvalitativ/kategorisk variabel med r mulige kategorier til (r-1) dummy variabel. Kategorien uden dummy-variabel kaldes reference-kategorien.

16
SPSS Output

17
Vekselvirkning / Interaktion
Vi kan introducere en vekselvirkning mellem kvalitative og kvantitative variable. Y, XHøjde og XKvinde som før. Introducer: XHøjde,Kvinde = XHøjde∙XKvinde Model

18
Fortolkning Når XKøn = Mand: Når XKøn = Kvinde:
bHøjde,Kvinde beskriver forskellen i hældningen mellem de to regressionslinjer.

19
Nu Som Figur! Linie for X2=0 Linie for X2=1 b0 b0+b2 Y Hældning = b1
Hældning = b1+b3 b0+b2

20
SPSS I SPSS definerer vi en ny variabel ’højde*køn’ vha. ’compute’ funktionen. Teste hypotesen H0: b Højde,Køn = 0 Konklusion: Vi afviser H0 , dvs der er en veksel-virkning.

21
Mere Vekselvirkning Interaktion opnås generelt ved at indføre nye variable, der er produktet af eksisterende variable. Interaktion med kvalitativ variabel med mere end to kategorier: Indfør interaktions parameter for hver kategori på nær reference-kategorien.

22
Generelle Lineære Modeller
For at undgå at skulle kode en masse binære dummy-variable, kan man i SPSS bruge Analyze → General Linear Model → Univariate Kategoriske variable Kontinuerte variable

25
Modelkontrol Antag vi har data indsamlet under to forskellige omstændigheder, fx to forskellige årtier. Lad XÅrti være en dummy-variabel, der angiver årtiet. Ved at lade XÅrti vekselvirke med andre variable i modellen, kan man undersøge om sammenhængen mellem Y og de forklarende variable har ændret sig statistisk signifikant fra det ene årti til det andet.

26
Kun Kvalitativ Forklarende Variabel
Y og XLøn, XMellem og XHøj som før. Model: Fortolkning: Vægten af folk i de tre grupper er normalfordelt, med samme varians, men med forskellig middel værdi: Alias: Variansanalyse!

28
Polynomiel regression
Nogle gange er sammenhængen mellem Y og en enkelt forklarende variabel X utilstrækkeligt beskrevet ved en ret linie, men bedre ved et polynomie. I disse tilfælde bruger vi polynomiel regression, hvor modellen er på formen Modellen er stadig lineær!!! Et m’te grads polynomie

29
Polynomiel Regression: Illustration
2. grads polynomie 3. grads polynomie Y Y $ y b X = + 1 $ y b X = + 1 $ ( ) y b X = + < 1 2 $ y b X = + 1 2 3 X1 X1 Brug kun polynomiel regression, hvis der er et godt argument for det – fx relevant baggrundsviden. Brug helst ikke over 2. grads polynomie (dvs X2) og aldrig mere end 5. grads polynomie (dvs X5) .
 y. b. X. = + < $ y. b. X. = X1. X1. Brug kun polynomiel regression, hvis der er et godt argument for det – fx relevant baggrundsviden. Brug helst ikke over 2. grads polynomie (dvs X2) og aldrig mere end 5. grads polynomie (dvs X5) .")
30
Polynomiel Regression som Modelkontrol
Vi har en forventning om at sammenhængen mellem Y og X er lineær. Et simpelt tjek er at tilføje det kvadratiske led X2 til modellen. Hvis X2 ledet ikke er signifikant har vi lidt mere grund til at tro på antagelsen om lineær sammenhæng.

31
Skabe X2 i SPSS På baggrund af variablen ’hojdeim’ hoejdeim2=hojdeim*hojdeim

33
Scatterplot og estimater
Et 2. grads polynomie tilpasset data →

34
Modellen forklarer kun ca 38% af variationen – ikke imponerende.
…men modellen er stadig ”besværet værd”.

35
Polynomiel regression: Eksempel
Body Mass Index: BMI=v/h2, hvor v er vægten målt i kg og h er højden målt i meter. Omskrivning: v=BMI∙h2. Model: hvor Y er vægten og X er højden. I SPSS skabes en ny variabel X2 vha. Transform→Compute...

36
Polynomiel regression med mere end en variabel
Det er muligt at anvende polynomier bestående af mere end en variabel. Fx to variable X1 og X2 – herved kan regressions-fladen fx få form som en paraboloide.

37
Ikke-lineære modeller og transformation
For nogle ikke-lineære modeller er det muligt at transformere modellen, så den bliver lineær. Vi skal se på Den multiplikative model Den eksponentielle model Den reciprokke model

38
Den Multiplikative Model
hvor ε er et fejlled. Logaritme-transformation: Vi tager (den naturlige) logaritme på begge sider af ligningen: Vi har nu en lineær model! Hvis logε ~ N(0,σ2) så kan vi udføre multipel lineær regression som sædvanligt! Vi skal bare logaritme-transformere vores variable først.
 logaritme på begge sider af ligningen: Vi har nu en lineær model! Hvis logε ~ N(0,σ2) så kan vi udføre multipel lineær regression som sædvanligt! Vi skal bare logaritme-transformere vores variable først.")
39
Den Eksponentielle Model
En logaritme transformation senere: Vi antager logε ~ N(0,σ2) Vi logaritme-transformerer kun Y, men ikke X1 og X2! Derefter kan vi foretage almindelig multipel lineær regression.
 Vi logaritme-transformerer kun Y, men ikke X1 og X2! Derefter kan vi foretage almindelig multipel lineær regression.")
40
Den Eksponentielle Model - fortolkning
Antag vi har estimeret Fortolkning af bk=3.2: Hvis xk stiger med 1 (og alle andre x’er holdes fast), så stiger Y med en faktor e3.2.
, så stiger Y med en faktor e3.2.")
41
Den Reciprokke Model Hvis så er
Tag reciprokværdien af Y og lad X’erne være. Kør derefter multipel lineære regression som sædvanligt.

42
Variansstabiliserende transformationer
I tilfælde, hvor residualerne ser heteroskedastiske ud, kan man forsøge sig med følgende transformationer: Kvadratrods-transformation: god når variansen er proportional med middelværdien. Logaritme-transformation: god når variansen er proportional med middelværdien i 2. Reciprokke-transformation: god når variansen er proportional med middelværdien i 4. y

Lignende præsentationer