Download præsentationen
Præsentation er lastning. Vent venligst

1
Statistik Lektion 15 Mere Lineær Regression
Modelkontrol Prædiktion Multipel Lineære Regression

2
Simpel Lineær Regression - repetition
Model: Spørgsmål: ”Afhænger y lineært af x ?”. Systematisk komponent + Stokastisk komponent

3
Estimation - repetition
Vha. Mindste Kvadraters Metode finder vi regressionslinjen hvor Residual:

4
Kovarians og Korrelation
Definition af kovarians: Cov(X,Y)=E[(EX-μX )(EY-μY)] Definition af korrelationskoefficient: r beskriver i hvor høj grad der er en lineær sammenhæng mellem X og Y. Estimat af r :
=E[(EX-μX )(EY-μY)] Definition af korrelationskoefficient: r beskriver i hvor høj grad der er en lineær sammenhæng mellem X og Y. Estimat af r :")
5
Forklaret og uforklaret afvigelse
Yi’s afvigelse fra kan opdeles i to: Y Uforklaret afvigelse Totale afvigelse Forklaret afvigelse X

6
Den totale variation Den totale variation for data er
”Variationen i data omkring datas middelværdi” SST = Sum of Squares Total

7
Total og forklaret variation - illustration
Y X Den totale variation ses når vi “kigger langs” x-aksen Den uforklarede variation ses når vi “kigger langs” regressionslinien

8
Opslitning af den totale variation
Den totale variation kan opslittes: er den uforklarede variation. er den forklarede variation. SSR = Sum of Squares Regression

9
Total og forklaret variation
Opsplitning af variationen

10
Determinations koeffcienten
Determinations Koeffcienten: Andelen af den totale variation, der er forklaret. Pr definition: 0 ≤ r2 ≤ 1. Jo tættere r2 er på 1, jo mere af variationen i data er forklaret af modellen. r2 >0.8 er godt! … r2 meget tæt på 1 er dog mistænkeligt.

11
Eksempler på r2 Y Y Y X X X SST SST SST SSE SSE SSR SSR r2 = 0

12
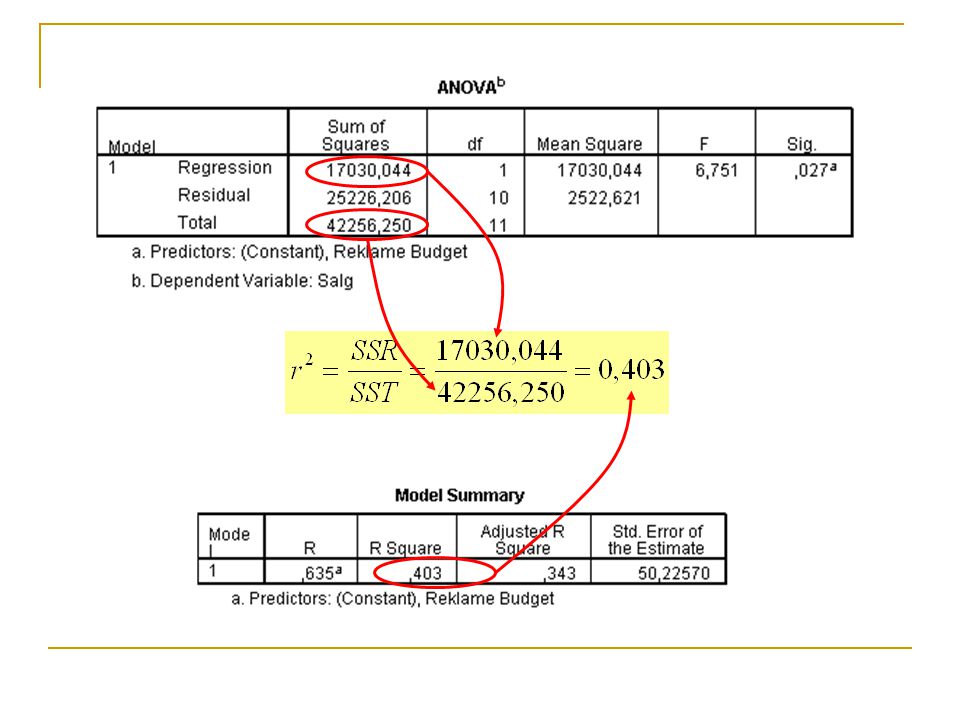
Eksempel: Reklamebudget vs salg

14
Modelkontrol For at kunne stole på test og estimater skal vi sikre os, at modellens antagelser er overholdt! Er der en lineær sammenhæng mellem X og Y ? Er fejlleddene ε1,…, εn uafhænige? Følger fejlleddene ε1,…, εn alle N(0,s2) ?
")
15
Residualanalyse Bemærk at residualet er et estimat af fejlledet ei.
Dvs. ei’erne groft sagt skal opføre sig som uafhængige N(0,s2) variable! Grafisk kontrol: Plot ei’erne mod xi eller .
 variable! Grafisk kontrol: Plot ei’erne mod xi eller .")
16
Residualplot Residualer Residualer ٪ √ Homoskedastisk: Residualerne ser ud til at variere lige meget for alle x eller . Desuden er residualerne ufahængige af hinanden og x. Heteroskedastisk: Variansen for residualerne ændrer sig når x ændrer sig. Residualer Residualer ٪ ٪ Tid Residualerne udviser lineær trend med tiden (ellern anden variabel vi ikke har brugt). Dette indikerer at tid skulle inkluderes i modellen. Det buede mønster indikerer en underlæggende ikke-lineær sammenhæng.
. Dette indikerer at tid skulle inkluderes i modellen. Det buede mønster indikerer en underlæggende ikke-lineær sammenhæng.")
17
TV-Statistik-Køkken Jeg har snydt og lavet mit eget data…
Det ligner reklame/salg data, men med flere observationer (n=30).
.")
18
Residualer i SPSS I ’Linear Regression’ vinduet vælges ’Save…’
I ’Save’ vinduet vælges ’Unstandardized’ både under ’Reresiduals’ (ei’erne) og ’Predicted Values’ ( ’erne) .
 og. ’Predicted Values’ ( ’erne) .")
19
Efter endt regression skaber SPSS to nye søjler i ’Data Editor’, der indeholder
residualer (’RES_1’) prædiktioner (’PRE_1’) . Derefter kan man fx lave scatter plots.
 prædiktioner (’PRE_1’) . Derefter kan man fx lave scatter plots.")
20
Scatter plot af residualer (ei’erne) mod ’højde’ (xi’erne) (øverst) residualer (ei’erne) mod prædiktionerne ( ’erne) (nederst). Ser jo ganske usystematisk ud!

21
Grafiske check for Normalfordeling
For at tjekke holdbarheden af antagelsen om normalfordelte fejlled: ( εi~N(0,σ2) ) Lav et histogram over residualerne og se efter om det normalfordelt ud. Lave et normalfordelingsplot (Q-Q plot). Lav et formelt χ2-test for ”goodness of fit” til en normalfordeling for residualerne (Kapitel 14)
 ) Lav et histogram over residualerne og se efter om det normalfordelt ud. Lave et normalfordelingsplot (Q-Q plot). Lav et formelt χ2-test for goodness of fit til en normalfordeling for residualerne (Kapitel 14)")
22
Histogram af residualer
Det ser jo ca normalfordelt ud…

23
Normalfordelingsplot (Q-Q plot)
For hvert residual ei udregner vi hvor li er antallet af residualer der er mindre end ei, og mi er antallet af residualer med samme værdi som ei. For hvert qi finder vi zi , så P(Z≤ zi )= qi , hvor Z~N(0,1). Hvis ei’erne er normalfordelte vil et plot af (ei, zi) ligge på en ret linie.
= qi , hvor Z~N(0,1). Hvis ei’erne er normalfordelte vil et plot af (ei, zi) ligge på en ret linie.")
24
Normalfordelingsplot (Q-Q plot)
Hvis alle ei’erne er forskellige kan vi bruge en tegning: zi’erne opnås ved at inddele normalfordelingen i n+1 ”lige store stykker”. Areal = 1/(n+1) z5
 z5.")
25
Vælg ’Analyze → Descriptive Statistics → Q-Q plots’
Ser helt fint ud – snor sig ikke alt for systematisk omkring linjen.

26
Prædiktion i SLR-modellen
Punktprædiktion: Hvilken værdi vil y forventeligt antage, hvis x antager en bestemt værdi, fx x=10 ? Svar: Dvs. vi prædikterer som bedste bud på punktets værdi. Bedst ikke at prædiktere for x–værdier for langt fra, hvor vi har data. Ganske simpelt ved at indsætte x i den estimerede regressions linje!

27
Prædiktionsinterval for observationen
Et (1-α)100% prædiktions interval for Y|X=x er Hvor s=√MSE. Et (1-α)100% konfidens interval for E(Y|X=x) er
100% prædiktions interval for Y|X=x er. Hvor s=√MSE. Et (1-α)100% konfidens interval for E(Y|X=x) er.")
28
Prædiktionsbånd Y Prædiktionsbånd for E[Y|X] Regressionslinje Prædiktionsbånd for Y|X X Prædiktionsbåndene fremkommer ved at betragte konfidensintervallets endepunkter som funktion af x.
![Prædiktionsbånd Y. Prædiktionsbånd for E[Y|X] Regressionslinje. Prædiktionsbånd for Y|X. X.](http://slideplayer.dk/slide/2860159/10/images/28/Pr%C3%A6diktionsb%C3%A5nd+Y.+Pr%C3%A6diktionsb%C3%A5nd+for+E%5BY%7CX%5D+Regressionslinje.+Pr%C3%A6diktionsb%C3%A5nd+for+Y%7CX.+X..jpg "Prædiktionsbåndene fremkommer ved at betragte konfidensintervallets endepunkter som funktion af x.")
29
Multipel Lineær Regression
Data: Sæt af observationer (x1i , x2i , …, xki , yi ) , i = 1,…,n yi er den afhængige variabel x1i , x2i , …, xki er de k forklarende/uafhængige forklarende variable for yi. Model: Yi = β0 + β1x1i +…+ βkxki + εi ε1 ,…,εn IID εi ~ N(0,σ2) E[Yi | x ] = β0 + β1x1 +…+ βkxk (lineær middelværdi-struktur)
 , i = 1,…,n. yi er den afhængige variabel. x1i , x2i , …, xki er de k forklarende/uafhængige forklarende variable for yi. Model: Yi = β0 + β1x1i +…+ βkxki + εi. ε1 ,…,εn IID εi ~ N(0,σ2) E[Yi | x ] = β0 + β1x1 +…+ βkxk. (lineær middelværdi-struktur)")
30
Forudsætninger Lineær sammenhæng mellem Y og Xj. Xj’erne er faste tal
εi~N(0,σ2) (uafhængigt af x og andre ε) Xi’erne skal være lineært uafhængige
 (uafhængigt af x og andre ε) Xi’erne skal være lineært uafhængige.")
31
Eksempel Model for i’te persons vægt: Eksempel:
Y = Vægt Yi = Vægt for i’te person X1 = Højde X1i = Højde for i’te person X2 = Alder X2i = Alder for i’te person Model for i’te persons vægt:

32
Multipel regression – illustration (k = 2)
x2 y y ε 2 1 0 x1

33
Parameter fortolkninger
β0 = Værdi af E(Y| x1=x2=…=xk=0) βj = Konstant der siger, hvor meget E(Y|X) ændrer sig hvis xj vokser med 1 og alle andre xi’er forbliver uforandrede. Eks: β2 marginal ændring i vægt som funktion af marginal ændring i alder.
 βj = Konstant der siger, hvor meget E(Y|X) ændrer sig hvis xj vokser med 1 og alle andre xi’er forbliver uforandrede. Eks: β2 marginal ændring i vægt som funktion af marginal ændring i alder.")
34
Estimeret Model og Residualer
ei Model Estimeret model Residual x2 x1 y

35
Estimation: Mindste kvadraters metode
Minimer summen af de kvadrerede residualer Matematisk set samme procedure som i simpel lineær regression: Differentier med hensyn til bj , j=0,...,k og sæt de k+1 ligninger lig nul. Resultat: (k+1) ligninger med (k+1) ubekendte. Løs!! (kræver mere avanceret matematik og ekstra meget te på kanden)
 ligninger med (k+1) ubekendte. Løs!! (kræver mere avanceret matematik og ekstra meget te på kanden)")
36
Multipel Lineær Regression i SPSS
En måde at lave multipel lineær regression på er vha. ’Linear Regression’ funktionen, hvor I blot indsætter flere variable som ’Independent’.

37
Eksempel Model: yi = Vægt for i’te person
x1i = Højde og x2i = Alder for i’te person. Estimerede regressionslinje:

38
Estimat af s2 – Fejlleds-variansen
Estimatoren er unbiased.

39
Test: ”Er modellen umagen værd”?
(Vi kan lige så godt sige, at y’erne alle har en og samme middelværdi) Hypoteser H0: b1 = b2 = …= bk = 0 H1: Mindst et bj ≠ 0 Hvis H0 er sand: MSR = SSR/k også et estimat af s2. Hvis H0 ej sand: Så er MSR generelt større end s2. Hvis H0 sand: MSR/MSE ~ F(k,n-k-1) (Der er en lineær sammenhæng mellem y og mindst ét af xj’erne)
 Hypoteser. H0: b1 = b2 = …= bk = 0. H1: Mindst et bj ≠ 0. Hvis H0 er sand: MSR = SSR/k også et estimat af s2. Hvis H0 ej sand: Så er MSR generelt større end s2. Hvis H0 sand: MSR/MSE ~ F(k,n-k-1) (Der er en lineær sammenhæng mellem y og mindst ét af xj’erne)")
40
ANOVA Tabellen Jo større F=MSR/MSE er, jo mindre tror vi på H0.
Source of variation Sums of squares df Mean Squares F-ratio P-værdi Regression SSR k MSR=SSR/k MSR/MSE ? Error SSE n-k-1 MSE= SSE/(n-k-1) Total SST n-1 Jo større F=MSR/MSE er, jo mindre tror vi på H0. P-værdien er sandsynligheden for at observere en større F værdi ”næste gang”, hvis H0 er sand.
 Total. SST. n-1. Jo større F=MSR/MSE er, jo mindre tror vi på H0. P-værdien er sandsynligheden for at observere en større F værdi næste gang , hvis H0 er sand.")
41
Eksempel (fortsat…) F = MSR / MSE = 104615,0 / 111,98 = 934,23
P-værdien er mindre end 0,05, så afviser vi H0 hypotesen, dvs. Vægt har en lineær sammenhæng med enten Højde eller vægt – eller begge.

42
Test for regressionsparametre
Som i simpel lineær regression har vi hvor σ(bi)2 estimeres ved s(bi)2. Udregningen af s(bi)2 overlader vi til SPSS.
2 estimeres ved s(bi)2. Udregningen af s(bi)2 overlader vi til SPSS.")
43
Test for regressionsparametre
Test for hypotesen Teststørrelse: Problem: Som ved varians-analysen har vi problemer med det samlede signifikans-niveau når vi laver mange test. (Ingen lineær sammenhæng mellem y og xi)
")
44
Eksempel Betragt H0: β1=0 (Ingen lineær samh. med højde) H1: β1≠0
t-teststørrelsen: Da P-værdien er mindre end 0.05, forkaster vi H0.

Lignende præsentationer
>")


















