Download præsentationen
Præsentation er lastning. Vent venligst

1
Rosalind Franklin f. 1920 – d.1958 Francis Harry Compton Crick
Maurice Hugh Frederick Wilkins f.1916 – d. 2004 James Dewey Watson f. 1928 Rosalind Franklin's røntgen diffraktions billede af DNA, 1953

2
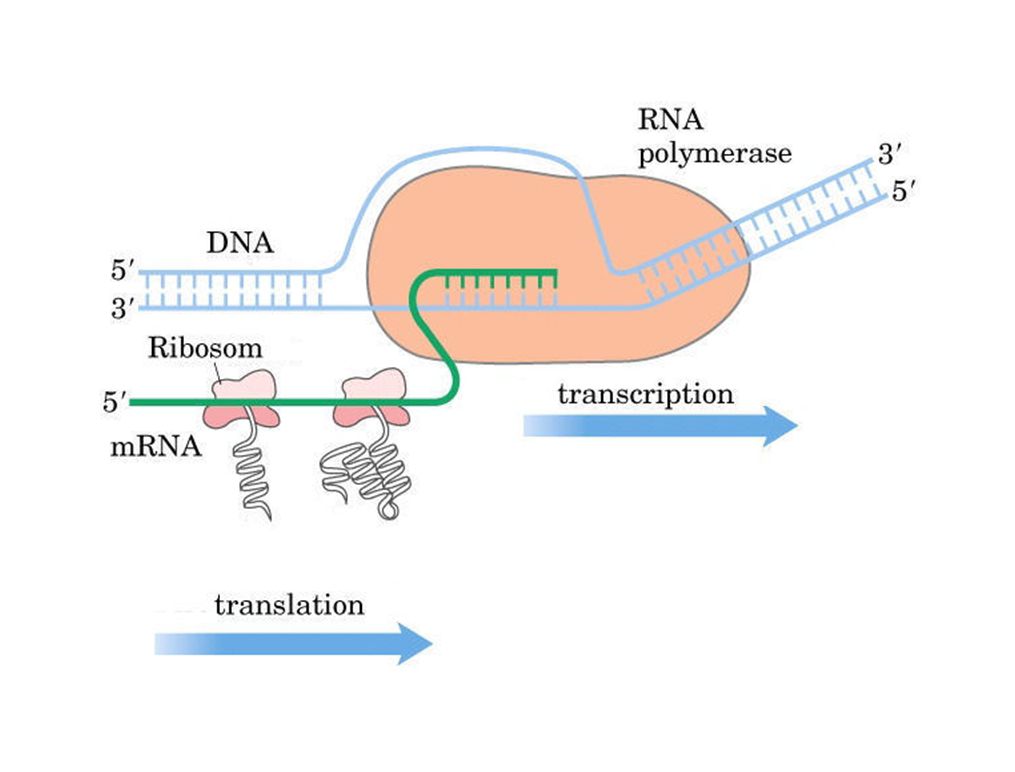
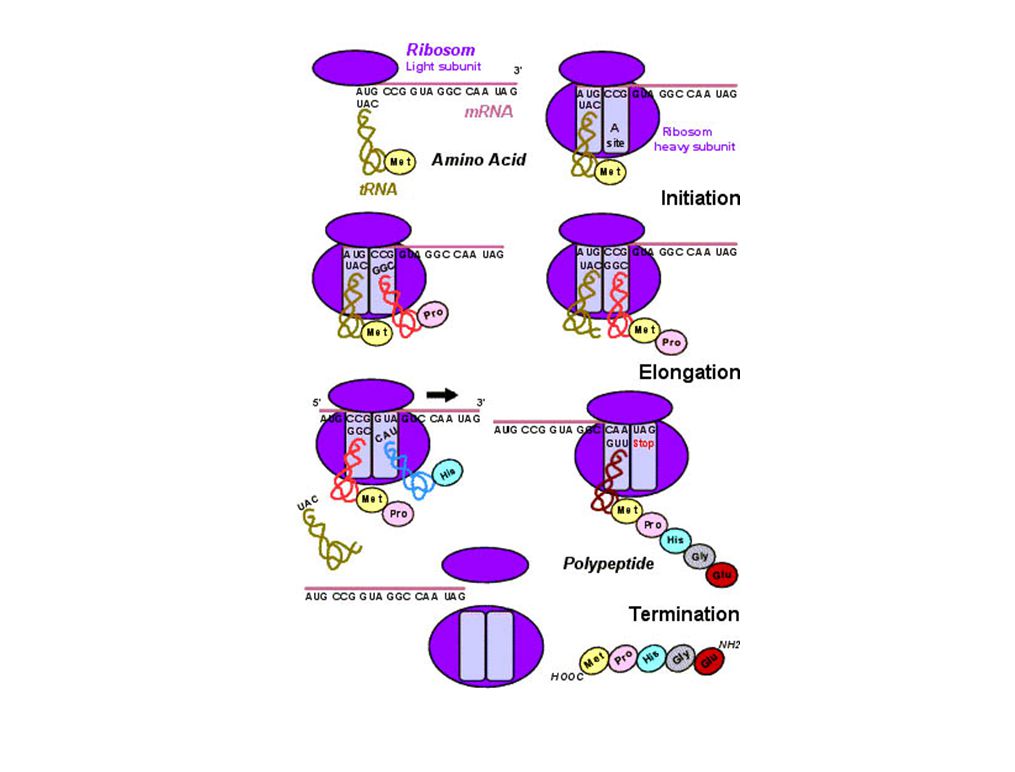
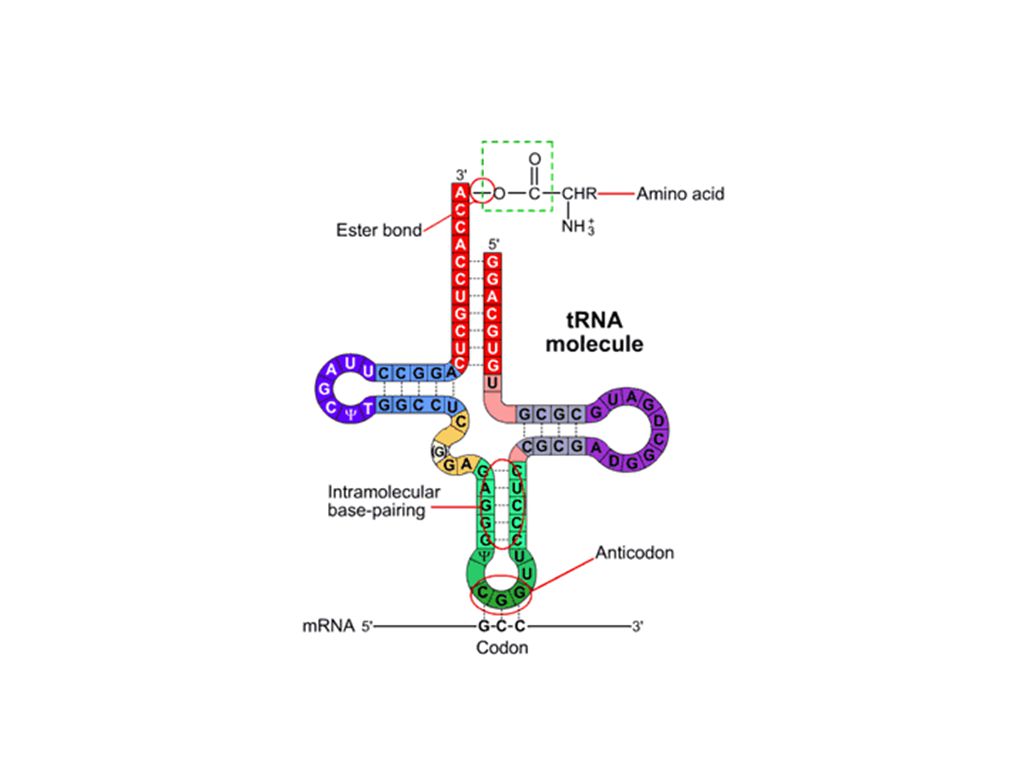
1. REPLICATION (DNA SYNTESE) 2. TRANSKRIPTION (RNA SYNTESE)
DET CENTRALE DOGME 2 3 DNA RNA PROTEIN 1 DNA Genetic diseases occur because of mutations in DNA. Many of these mutations affect the repair of other mutations that occur during DNA replication or at other times, which in turn affect the flow of genetic information from DNA to RNA (transcription and processing) and from RNA to protein synthesis (translation). Many of these mutations also affect the structures of the resulting proteins, affecting their functions. 1. REPLICATION (DNA SYNTESE) 2. TRANSKRIPTION (RNA SYNTESE) 3. TRANSLATION (PROTEIN SYNTESE)
 and from RNA to protein synthesis (translation). Many of these mutations also affect the structures of the resulting proteins, affecting their functions. 1. REPLICATION (DNA SYNTESE) 2. TRANSKRIPTION (RNA SYNTESE) 3. TRANSLATION (PROTEIN SYNTESE)")
4
Dobbelt-strenget DNA

5
Basernes Struktur Purines Pyrimidines
Be familiar with the structures of the purine bases, adenine (A) and guanine (G); and the pyrimidine bases, thymine (T) and cytosine (C). A common base modification in DNA results from the methylation of cytosine, giving rise to 5-methylcytosine (5mC). As we shall see subsequently, 5mC is highly mutagenic. It is believed that this methylation functions to regulate gene expression because 5-methylcytosine (5mC) residues are often clustered near the promoters of genes in so-called "CpG islands.“ (Along one strand of DNA the nucleotides are sometimes indicated by the base followed by a phosphate or “p” such as ApTpCpCpGpApCpTpGpGp - this sequence contains one CpG site.) The problem that arises from these methylations is that subsequent deamination of a 5mC results in the production of thymine, which is not foreign to DNA. As such, 5'-mCG-3' sites (or mCpG sites) are "hot-spots" for mutation, and when mutated are a common cause of cancer.
 and guanine (G); and the pyrimidine bases, thymine (T) and cytosine (C). A common base modification in DNA results from the methylation of cytosine, giving rise to 5-methylcytosine (5mC). As we shall see subsequently, 5mC is highly mutagenic. It is believed that this methylation functions to regulate gene expression because 5-methylcytosine (5mC) residues are often clustered near the promoters of genes in so-called CpG islands. (Along one strand of DNA the nucleotides are sometimes indicated by the base followed by a phosphate or p such as ApTpCpCpGpApCpTpGpGp - this sequence contains one CpG site.) The problem that arises from these methylations is that subsequent deamination of a 5mC results in the production of thymine, which is not foreign to DNA. As such, 5 -mCG-3 sites (or mCpG sites) are hot-spots for mutation, and when mutated are a common cause of cancer.")
6
[structure of deoxyadenosine]
Nucleoside [structure of deoxyadenosine] When a base, such as adenine, is linked to a deoxyribose sugar through a glycosidic bond, the structure is a nucleoside, in this case deoxyadenosine. The deoxyribose sugar lacks a hydroxyl group on the 2' carbon, hence deoxy. This is in contrast to the presence of a hydroxyl at that position in the ribose sugar found in RNA. When the deoxyribose sugar is phosphorylated, on either the 3' or the 5' position (or both), the structure is a nucleotide, in this case deoxyadenosine-5'-phosphate. The precursors of DNA synthesis are deoxynucleoside-5'-triphosphates or dNTPs. Nucleotide
![[structure of deoxyadenosine]](http://slideplayer.dk/slide/2830460/10/images/6/%5Bstructure+of+deoxyadenosine%5D.jpg "Nucleoside. [structure of deoxyadenosine] When a base, such as adenine, is linked to a deoxyribose sugar through a glycosidic bond, the structure is a nucleoside, in this case deoxyadenosine. The deoxyribose sugar lacks a hydroxyl group on the 2 carbon, hence deoxy. This is in contrast to the presence of a hydroxyl at that position in the ribose sugar found in RNA. When the deoxyribose sugar is phosphorylated, on either the 3 or the 5 position (or both), the structure is a nucleotide, in this case deoxyadenosine-5 -phosphate. The precursors of DNA synthesis are deoxynucleoside-5 -triphosphates or dNTPs. Nucleotide.")
7
Base +deoxyribose +phosphat
Nomenklatur Nucleosid Nucleotid Base +deoxyribose phosphat Puriner adenin adenosin guanin guanosin Pyrimidiner thymin thymidin cytosin cytidin +ribose uracil uridin This table lists the common bases and their corresponding names when in the nucleoside or nucleotide form. Hypoxanthine (inosine) is seen in DNA following deamination of adenine (adenosine). It is also seen in transfer RNA as a common, functionally important posttranscriptional modification. Uracil (uridine) is found in RNA, instead of thymine (thymidine), which is specific for DNA.
 is seen in DNA following deamination of adenine (adenosine). It is also seen in transfer RNA as a common, functionally important posttranscriptional modification. Uracil (uridine) is found in RNA, instead of thymine (thymidine), which is specific for DNA.")
8
3’,5’-phosphodiester bond
ii). Structure of the DNA double helix DNA Struktur polynucleotid kæde 5’ The polynucleotide chain is formed by linking nucleotides through 3',5'-phosphodiester bonds. 3’ polynucleotide chain 3’,5’-phosphodiester bond
. Structure of the. DNA double helix. DNA Struktur. polynucleotid kæde. 5’ The polynucleotide chain is formed by linking nucleotides through 3 ,5 -phosphodiester bonds. 3’ polynucleotide chain. 3’,5’-phosphodiester bond.")
9
Hydrogen binding af baser
A-T base pair Hydrogen binding af baser The DNA double helix requires that the two polynucleotide chains be base-paired to each other. This slide shows an adenine-thymine (A-T) base pair (which is the A and which is the T?); and a guanine-cytosine (G-C) base pair (which is the G and which is the C?). Because of base pairing, the polynucleotide chains in double-stranded DNA are complementary to each other. G-C base pair Chargaff’s rule: The content of A equals the content of T, and the content of G equals the content of C in double-stranded DNA from any species
 base pair (which is the A and which is the T ); and a guanine-cytosine (G-C) base pair (which is the G and which is the C ). Because of base pairing, the polynucleotide chains in double-stranded DNA are complementary to each other. G-C base pair. Chargaff’s rule: The content of A equals the content of T, and the content of G equals the content of C. in double-stranded DNA from any species.")
10
Genom størrelse i nucleotid par (basepar)
plasmider vira bakterier svampe planter alger insekter bløddyr fisk Størrelsen af det humane genom er ca. 3 X 109 bp. Det humane genom indeholder ca. 30,000 to 40,000 gener. On June 26, 2000, the Human Genome Project and Celera Genomics Corp. jointly announced that the sequencing of the human genome was all but completed. A so-called rough draft of approximately 90% of the genome was completed and ready for release to scientists and medical researchers at that time. A rough draft was released to make the sequence available as soon as possible while completion of the remaining sequence took place. What still needs to be done is to fill in some difficult-to-sequence gaps and to find "typographical errors" in the sequence. Knowing the complete sequence of the human genome will allow medical researchers to more easily find disease-causing genes. In addition, it should become possible to understand how differences in our DNA sequences from individual to individual may affect our predisposition to diseases and our ability to metabolize drugs. Because the human genome has ~3 billion bp of DNA and there are 23 pairs of chromosomes in diploid human cells, the average metaphase chromosome has ~130 million bp DNA. amfibier reptiler fugle Pattedyr 104 105 106 107 108 109 1010 1011

11
Gen struktur promoter region exon exon exon +1 introns (mellem exons)
transkriberet region This slide shows the structure of a typical human gene and its corresponding messenger RNA (mRNA). Most genes in the human genome are called "split genes" because they are composed of "exons" separated by "introns." The exons are the regions of genes that encode information that ends up in mRNA. The transcribed region of a gene (double-ended arrow) starts at the +1 nucleotide at the 5' end of the first exon and includes all of the exons and introns (initiation of transcription is regulated by the promoter region of a gene, which is upstream of the +1 site). RNA processing (the subject of a another lecture) then removes the intron sequences, "splicing" together the exon sequences to produce the mature mRNA. The translated region of the mRNA (the region that encodes the protein) is indicated in blue. Note that there are untranslated regions at the 5' and 3‘ ends of mRNAs that are encoded by exon sequence but are not directly translated. mRNA struktur 5’ 3’ translateret region
. Most genes in the human genome are called split genes because they are composed of exons separated by introns. The exons are the regions of genes that encode information that ends up in mRNA. The transcribed region of a gene (double-ended arrow) starts at the +1 nucleotide at the 5 end of the first exon and includes all of the exons and introns (initiation of transcription is regulated by the promoter region of a gene, which is upstream of the +1 site). RNA processing (the subject of a another lecture) then removes the intron sequences, splicing together the exon sequences to produce the mature mRNA. The translated region of the mRNA (the region that encodes the protein) is indicated in blue. Note that there are untranslated regions at the 5 and 3‘ ends of mRNAs that are encoded by exon sequence but are not directly translated. mRNA struktur. 5’ 3’ translateret region.")
12
Strukturen af forskellige gener
histone total = 400 bp; exon = 400 bp b-globin total = 1,660 bp; exons = 990 bp HGPRT (HPRT) This figure shows examples of the wide variety of gene structures seen in the human genome. Some (very few) genes do not have introns. One example is the histone genes, which encode the small DNA-binding proteins, histones H1, H2A, H2B, H3, and H4. Shown here is a histone gene that is only 400 base pairs (bp) in length and is composed of only one exon. The beta-globin gene has three exons and two introns. The hypoxanthine-guanine phosphoribosyl transferase (HGPRT or HPRT) gene has nine exons and is over 100-times larger than the histone gene, yet has an mRNA that is only about 3-times larger than the histone mRNA (total exon length is 1,263 bp). This is due to the fact that introns can be very long, while exons are usually relatively short. An extreme example of this is the factor VIII gene which has numerous exons (the blue boxes and blue vertical lines). total = 42,830 bp; exons = 1263 bp faktor VIII total = ~186,000 bp; exons = ~9,000 bp
 This figure shows examples of the wide variety of gene structures seen in the human genome. Some (very few) genes do not have introns. One example is the histone genes, which encode the small DNA-binding proteins, histones H1, H2A, H2B, H3, and H4. Shown here is a histone gene that is only 400 base pairs (bp) in length and is composed of only one exon. The beta-globin gene has three exons and two introns. The hypoxanthine-guanine phosphoribosyl transferase (HGPRT or HPRT) gene has nine exons and is over 100-times larger than the histone gene, yet has an mRNA that is only about 3-times larger than the histone mRNA (total exon length is 1,263 bp). This is due to the fact that introns can be very long, while exons are usually relatively short. An extreme example of this is the factor VIII gene which has numerous exons (the blue boxes and blue vertical lines). total = 42,830 bp; exons = 1263 bp. faktor VIII. total = ~186,000 bp; exons = ~9,000 bp.")
13
DNA Replication

17
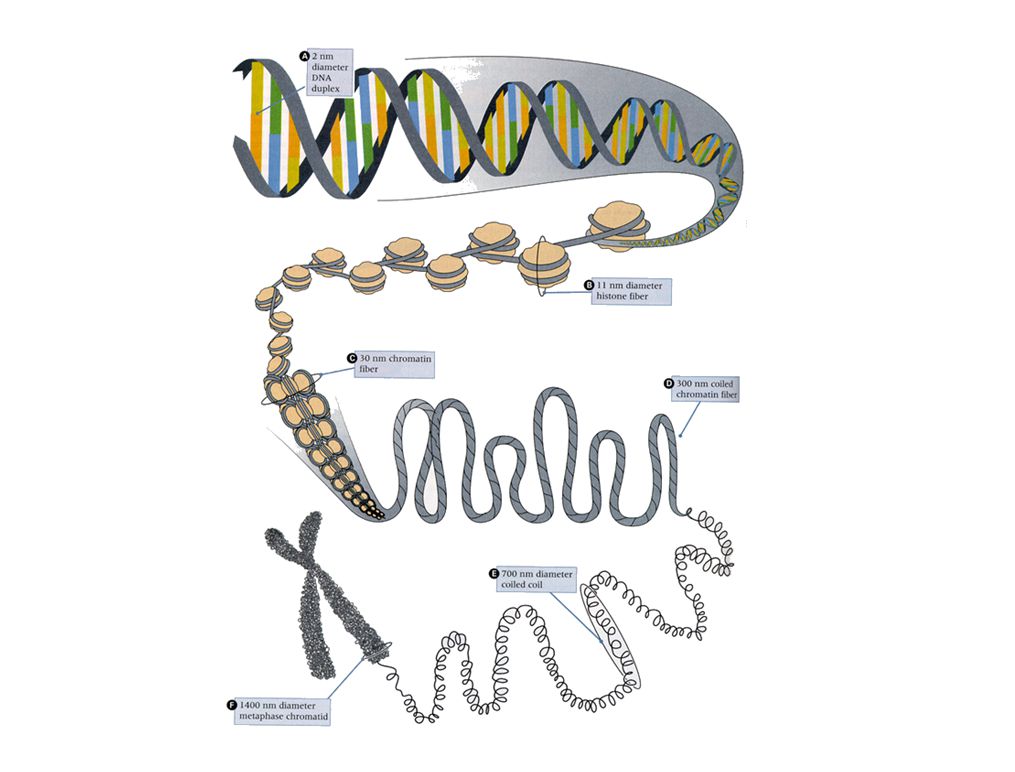
This high power electron micrograph shows the detailed structure of chromosome threads following a gentle preparation technique that involves removal of loosely bound chromosomal proteins while preserving the more tightly bound DNA-binding proteins. The appearance of a "beads on a string" structure is due to regularly spaced nucleosomes (see next slide). "Chromatin" is the biochemical term for DNA-protein complexes that are isolated from eukaryotic chromosomes. EM af et polysom

Lignende præsentationer








>")






.>")





