Download præsentationen
Præsentation er lastning. Vent venligst

1
Statistik Lektion 17 Multipel Lineær Regression
Polynomiel regression Ikke-lineære modeller og transformation Multi-kolinearitet Auto-korrelation og Durbin-Watson test

2
Multipel lineær regression
x1,x2,…,xk uafhængige variable (forklarende variable). Model: Dagens spørgsmål Hvad kan man gøre hvis sammenhængen mellem Y og X ikke er beskrevet ved en ret linie? I tilfælde af heteroskedasdiske data – hvad kan man da gøre? Er residualerne data auto-korrelerede?
. Model: Dagens spørgsmål. Hvad kan man gøre hvis sammenhængen mellem Y og X ikke er beskrevet ved en ret linie I tilfælde af heteroskedasdiske data – hvad kan man da gøre Er residualerne data auto-korrelerede")
3
Polynomiel regression
Nogle gange er sammenhængen mellem Y og en enkelt forklarende variabel X utilstrækkeligt beskrevet ved en ret linie, men bedre ved et polynomie. I disse tilfælde bruger vi polynomiel regression, hvor modellen er på formen Modellen er stadig lineær!!! (Et m’te grads polynomie)
")
4
Polynomiel Regression: Illustration
2. grads polynomie 3. grads polynomie Y Y X1 X1 Brug kun polynomiel regression, hvis der er et godt argument for det – fx relevant baggrundsviden. Brug helst ikke over 2. grads polynomie (dvs X2) og aldrig mere end 6. grads polynomie (dvs X6) .
 og aldrig mere end 6. grads polynomie (dvs X6) .")
5
Polynomiel Regression som Modelkontrol
Vi har en forventning om lineær sammenhængen mellem Y og X. Et simpelt tjek er at tilføje det kvadratiske led X2 til modellen. Hvis X2 ledet ikke er signifikant har vi lidt mere grund til at tro på antagelsen om lineær sammenhæng.

6
Polynomiel regression: Eksempel
Body Mass Index: hvor v er vægten målt i kg og h er højden målt i meter. Omskrivning: v = BMI ∙ h2. Model: hvor Y er vægten og X er højden. I SPSS skabes en ny variabel X2 vha. Transform→Compute…

7
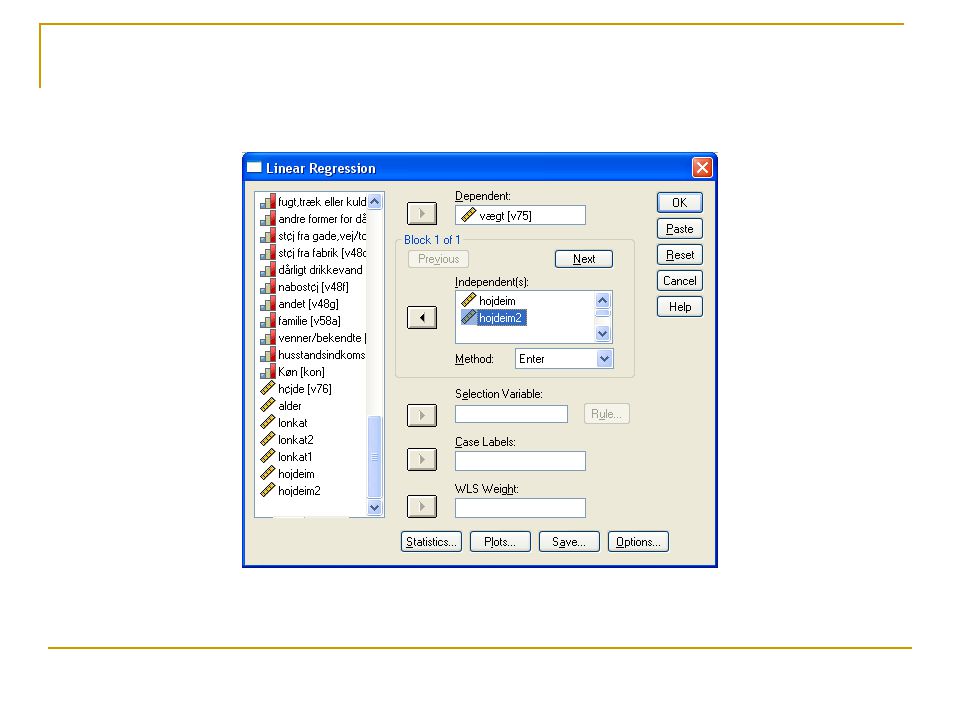
Skabe X2 i SPSS På baggrund af variablen ’hojdeim’ skabes
hoejdeim2 = hojdeim*hojdeim

9
Scatterplot og estimater
Et 2. grads polynomie tilpasset data →

10
Modellen forklarer kun ca 38% af variationen – ikke imponerende.
…men modellen er stadig ”besværet værd”.

11
Polynomiel regression med mere end en variabel
Det er muligt at anvende polynomier bestående af mere end en variabel. Fx to variable X1 og X2 – herved kan regressions fladen fx få form som en paraboloide.

12
Ikke-lineære modeller og transformation
For nogle ikke-lineære modeller er det muligt at transformere modellen, så den bliver lineær. Vi skal se på Den multiplikative model Den eksponentielle model Den reciprokke model

13
Den Multiplikative Model
hvor e er et fejlled. Logaritme-transformation: Vi tager (den naturlige) logaritme på begge sider af ligningen: Vi har nu en lineær model! Hvis loge ~ N(0,s2) så kan vi udføre multipel lineær regression som sædvanligt! Vi skal bare logaritme-transformere vores variable først.
 logaritme på begge sider af ligningen: Vi har nu en lineær model! Hvis loge ~ N(0,s2) så kan vi udføre multipel lineær regression som sædvanligt! Vi skal bare logaritme-transformere vores variable først.")
14
Den Multiplikative Model
Den multiplikative model kan skrives som hvor , osv. Eksempel: Vi kan omskrive BMI formlen (igen): hvor Y = log v og X = log h. Er mon β0 ≈ log(23) og β1 ≈ 2 ? ■ Model:
: hvor Y = log v og X = log h. Er mon β0 ≈ log(23) og β1 ≈ 2 ■ Model:")
15
Resultat β0 = 3,069 ”Forventet” β0 = ln(23)=3,13 β1 = 2,156 ”Forventet” β1 = 2 Fortolkning: v = e3,069h2,156 = h2,156 Bemærk: E(v|h) h2,156
 h2,156.")
16
Den Eksponentielle Model
En logaritme transformation senere: Vi antager loge ~ N(0,σ2) Vi logaritme-transformerer kun Y, men ikke X1 og X2! Derefter kan vi foretage almindelig multipel lineær regression.
 Vi logaritme-transformerer kun Y, men ikke X1 og X2! Derefter kan vi foretage almindelig multipel lineær regression.")
17
Den Eksponentielle Model - fortolkning
Antag vi har estimeret Fortolkning af bk = 3.2: Hvis xk stiger med 1 (og alle andre x’er holdes fast), så stiger Y med en faktor e3.2.
, så stiger Y med en faktor e3.2.")
18
Den Reciprokke Model Hvis så er
Tag reciprokværdien af Y og lad X’erne være. Kør derefter multipel lineære regression som sædvanligt.

19
Variansstabiliserende transformationer
I tilfælde, hvor residualerne ser heteroskedastiske ud, kan man forsøge sig med følgende transformationer: Kvadratrods-transformation: god når variansen er proportional med middelværdien. Logaritme-transformation: god når variansen er proportional med middelværdien i 2. Reciprokke-transformation: god når variansen er proportional med middelværdien i 4. y

20
Multikolinearitet To variable X1 og X2 er perfekt kolineære, hvis
for to reelle tal a og b. Corr(X1,X2) = 1 (eller -1) Eksempel: Perfekt kolinearitet (sjældent problem) X1 = Indkomst i kr. og X2 = Indkomst i $ Eksempel: Ret kolineære variable (reelt problem) X1 = Alder og X2 = Anciennitet
 = 1 (eller -1) Eksempel: Perfekt kolinearitet (sjældent problem) X1 = Indkomst i kr. og X2 = Indkomst i $ Eksempel: Ret kolineære variable (reelt problem) X1 = Alder og X2 = Anciennitet.")
21
Konsekvenser af Multikolinearitet
Variansen af regressions-koefficienterne (bj’erne) ”eksploderer”. Størrelsen på regressions-koefficienterne kan afvige meget fra hvad man ville forvente. Tilføje/fjerne variable resulterer i store ændringer i regressions-koefficienterne. Fjerne et data-punkt kan resultere i store forandringer i regressions-koefficienterne. I nogle tilfælde er F-testet signifikant mens ingen t-test er.
 eksploderer . Størrelsen på regressions-koefficienterne kan afvige meget fra hvad man ville forvente. Tilføje/fjerne variable resulterer i store ændringer i regressions-koefficienterne. Fjerne et data-punkt kan resultere i store forandringer i regressions-koefficienterne. I nogle tilfælde er F-testet signifikant mens ingen t-test er.")
22
Variance Inflation Factor (VIF)
Antag vores regressionsmodel allerede indeholder de forklarende variable X1,…,Xk. Hvor meget ekstra kolinearitet introduceres, hvis medtager en ekstra forklarende variabel Xh? Foretag en multipel lineær regression med Xh som afhængig variable og X1,…,Xk som forklarende. Lad Rh2 være den tilsvarende determinations koefficient. Da er VIF givet ved Jo mere Xh er kolinear med X1,…,Xk , jo højere Rh2 og jo højere VIF.

23
VIF: Eksempel Model: hvor X1 er højde og X2 er alder.
I SPSS: I ’Linear Regression’ vælger man ’Statistics…’ og der ’Colinearity diagnostics’. X1 og X12 ser ud til at være (indbyrdes) kolineare, mens X2 (som forventet) ikke ser ud til at være det.
 kolineare, mens X2 (som forventet) ikke ser ud til at være det.")
24
VIF: Eksempel - fortsat
Scatter-plot af mod

25
Multikolinearitet: Løsninger
Fjern en kolineær variabel fra modellen.

26
Auto-korrelation Antag at Xi svarer til i’te måling af variabel X, fx temperaturen kl. 12 på den i’te, fx dag. Lag-h auto-korrelationen er defineret ved dvs. korrelationen mellem temperaturer målt med h dages mellemrum. Bemærk: Vi har antaget at fejlledene er uafhængige, dvs. rh = Corr(ei , ei+h) = 0 for alle h. Dvs. vi forventer rh = Corr(ei , ei+h) ≈ 0 for alle h.
 = 0 for alle h. Dvs. vi forventer rh = Corr(ei , ei+h) ≈ 0 for alle h.")
27
Eksempler hvor residualerne udviser
Stærk auto-korrelation (øverst) Ringe auto-korrelation (nederst) Residualer Data
 Ringe auto-korrelation (nederst) Residualer. Data.")
28
Durbin-Watson Test Test for om lag-1 auto-korrelationen er nul
H0: r1 = 0 H1: r1 0 Teststørrelsen er Bemærk at d ikke er et stikprøve-estimatet af lag-1 auto-korrelationen

29
Kritiske værdier for Durbin-Watson
Efter at have udregnet d finder vi dL og dU i Tabel 7 i Appendix C. Derefter sammenligner vi d med punkterne i skemaet nedenfor. Er d i det grønne område forkaster vi H0. Positiv Autokorrelation Test uden Konklusion Ingen Autokorrelation Test uden Konklusion Negativ Autokorrelation d dL dU 4-dU 4-dL 4

30
Durbin-Watson: Eksempel
For n=100 og h=1 giver tabelopslag dL=1,65 og dU=1,69. Positiv Autokorrelation Test uden Konklusion Ingen Autokorrelation Test uden Konklusion Negativ Autokorrelation d dL dU 4-dU 4-dL 4 1,65 1,69 2,35 2,31 Her afviser vi H0 – dvs. ρ1≠0, altså auto-korrelation. Her kan vi ikke afvise H0 – dvs. igen auto-korrelation.

Lignende præsentationer