Download præsentationen
Præsentation er lastning. Vent venligst

1
Valg med Excel Fordelingsmetoder med Excel
Meningsmålinger og usikkerheder på disse. Matematikken bag. Meningsmålinger i en Excelskabelon.

2
Fordelingsmetoder med Excel
Afrunding Største brøks metode D'Hondts metode Saint Lagues metode

3
I skal lave et regneark med 3 af fordelingsmetoder.
I skal lave 1 fane til hver fordelingmetode. Fanerne skal navngives efter fordelingsmetoden. Metoderne beskrives her og I kan på videoerne se, hvorledes Excel kan anvendes til at beregne fordelingen udfra valgtallene ved kommunevalget i 2005. Disse ligger i et regneark på hjemmesiden, hvor også instruktionsvideoerne kan findes. Ved D’Hondts metode vælger vi at fordele lidt færre mandater og på opdigtede stemmetal.

4
Afrunding Det beregnes, hvor mange procent af vælgerne, der har stemt på partiet. Denne procentdel ganges med antallet af mandater. De fremkomne tal afrundes efter almindelige afrundingsregler.

5
Største brøks metode Det beregnes, hvor mange procent af vælgerne, der har stemt på partiet Denne procentdel ganges med antallet af mandater. Man tager heltalsdelen af de fremkomne tal. De resterende mandater fordeles ved at tildele mandaterne efter største rest.

6
D'Hondts metode Stemmetalllene for hvert parti deles med henholdsvis 1,2,3,4,5,.... Mandaterne fordeles derefter 1 efter 1 efter de største koefficienter indtil alle mandater er fordelt.

7
Modificeret Saint Legues:
Saint Legues metode Som D'Hondts metode blot deles istedet med 1,3,5,..... Modificeret Saint Legues: Her deles istedet for 1 først med 1,4 og derefter 3,5,...

8
Meningsmålinger Problemet: Svaret:
En normal meningsmåling består som regel af ca personer, som er blevet stillet ét eller flere spørgsmål – fx hvilket parti, de vil stemme på i morgen. Hvordan kan vi overhovedet sige noget om hele befolkningen ud fra kun 1000 personer? Svaret: Sandsynlighedsteori

9
1.1 Notation Et eksempel: Vilstrup Synovate giver DF 11,3% af stemmerne = en andel på 0,113 Men hvad er DFs stemmeandel i hele befolkningen? π = Andelen i hele befolkningen (populationsparameteren) = Stikprøvens estimat af andelen i befolkningen n = Stikprøvens størrelse
 = Stikprøvens estimat af andelen i befolkningen. n = Stikprøvens størrelse.")
10
1.2 Det sandsynlighedsteoretiske grundlag
Andelen i en given stikprøve er et stikprøvemål – dvs. noget der er beregnet på baggrund af en stikprøve Hvis man udtager mange stikprøver og beregner det samme mål, vil der være en vis variation i dem Man kan derfor vise dem i et stolpediagram, hvor hver stolpe viser, hvor mange stikprøver, der har fået en given værdi for målet Den fordeling, der herved fremkommer, kaldes stikprøvemålsfordelingen – og det er den vi er interesserede i

11
1.2 Den centrale grænseværdisætning
Hvis stikprøven er udtrukket simpelt tilfældigt, gælder det, at: Når n er tilstrækkelig stor, vil fordeling – uanset fordelingen i populationen – være omtrent normalfordelt med gennemsnit π og standardafvigelse (kaldes standardfejl)
")
12
En simulering 1 Vi vil prøve at simulere om CGS passer.
Dette vil vi gøre ved at simulere træk af kugler. Gå på hjemmesiden:

13
En simulering 2 Her kan computeren simulere en udtrækningsproces.
Hvis man fx indtaster: med tilbagelægning Kugler i alt: 10 antal Heraf røde 3 Seriens længde=100 Antal serier=1000 Og man kører simuleringen, så simulerer computeren følgende: Man har en beholder med 10 kugler i alt hvoraf 3 er røde. Man trækker en kugle og notere om den er røde eller ej. Kuglen lægges tilbage og man trækker på ny. Dette udføres 100 gange. Det samlede antal røde kugler noteres. Dette forsøg udføres nu 1000 gange og tallene i tabellen angiver hvordan fordelingen af antallet af røde kugler var i de 1000 forsøg.

14
En simulering 3 Dette kan vi overføre til meningsmåling, idet der hver gang vi spørger en person om hvilket parti han/hun stemmer på, er der den samme sandsynlighed for, at personen svarer fx A. Hvis man udtager 1000 stikprøver på hver100 personer, så vil tallene i tabellen fortælle, hvor mange personer der i hver stikprøve sagde, at de ville stemme på A.

15
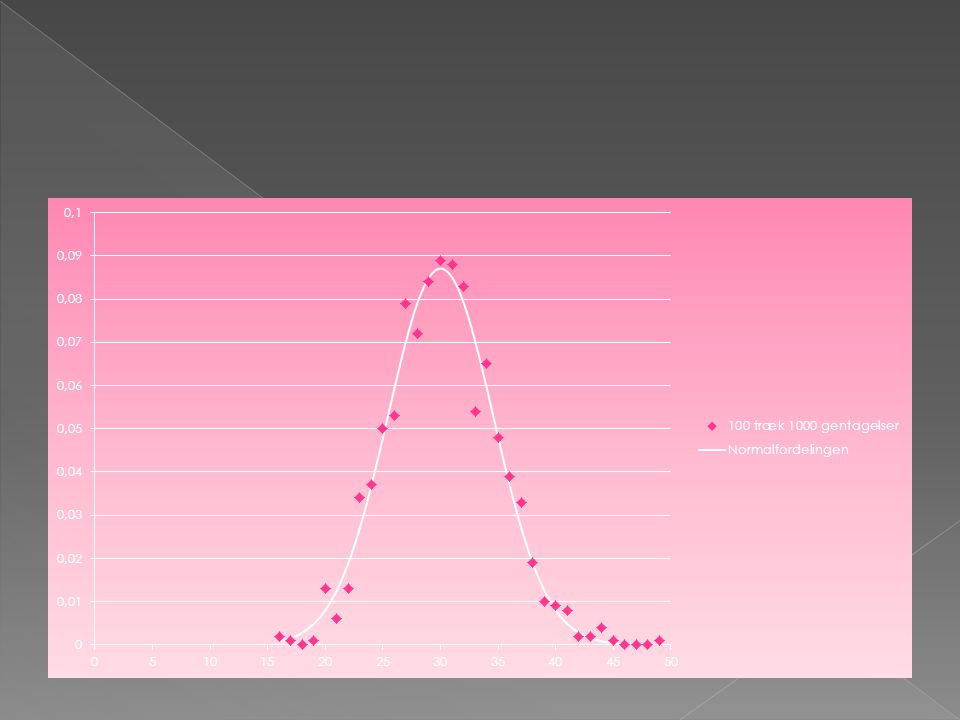
En simulering 4 Lav simuleringen med ovennævnte værdier.
Kopier tallene over i Excel. Antal røde kugler er jeres x-værdier. Lad frekvenserne være jeres y-værdier. Lav en graf. Dette skulle gerne ligne en normalfordeling.

16
simulering

17
En simulering 5 Ifølge CGS skulle dette nærme sig en normalfordeling med middelværdi 30 og standardafvigelse

18
En simulering 6: Vi kan tegne denne normalfordeling ved at taste =Normfordeling(A1;30;4,58,FALSK), hvor antallet af røde kugler står i A1. Kopier formlen hele vejen ned og tegn grafen. Passer fordelingen med data?
, hvor antallet af røde kugler står i A1. Kopier formlen hele vejen ned og tegn grafen. Passer fordelingen med data")
20
1.2 Den centrale grænseværdisætning
Og hvad kan vi så bruge det til? Vi kender ikke π, men vi ved, at når stikprøven er udtaget tilfældigt, så gælder CGS, og så følger stikprøvefordelingen normalfordelingen For normalfordelinger kan det vises, at 95% af fordelingen ligger inden for en afstand på ± 1,96 gange standardfejlen af gennemsnittet

21
1.2 Normalfordelingen 95% 2,5% 2,5% π

22
1.3 Konfidensintervaller
Vores fordeling er en fordeling af stikprøvemål for andelen π Dvs. hvis vi for hver stikprøve laver et interval på ± 1,96 gange standardfejlen rundt om estimatet af π, så vil det indeholde π i 95% af de gange, vi udtrækker en stikprøve For den enkelte stikprøve siger man, at intervallet indeholder π med 95% konfidens (= sikkerhed) Intervallet kaldes således et konfidensinterval og viser altså de værdier, hvor indenfor det er rimeligt sandsynligt, at π falder
 Intervallet kaldes således et konfidensinterval og viser altså de værdier, hvor indenfor det er rimeligt sandsynligt, at π falder.")
23
1.3 En lille detalje Beregning af standardfejlen forudsætter kendskab til π: I praksis estimeres denne dog ud fra stikprøven, så standardfejlen beregnes som

24
1.4 Konfidensinterval for andele: Definition
Et 95% konfidensinterval for π er defineret som Vi opstiller altså et interval, hvori π befinder sig med 95% konfidens Gælder som udgangspunkt kun for n>30 og 0,3 < π < 0,7

25
1.4 Definition (forts.) Generelt: n skal overstige 30
For π < 0,3 eller π > 0,7: Stikprøvemålsfordelingen skæv skærpet krav til n: Der skal mindst være 10 observationer både i den kategori vi måler andelen for – og i resten af gruppen – fx skal mindst 10 respondenter ville stemme på DF og mindst 10 respondenter på alle andre partier til sammen

26
1.5 Et eksempel Fx: Vilstrup Synovate i Politiken :
Estimat: Andel DF-vælgere = 0,113, n=1148 Et 95% konfidensinterval for andelen af DF-vælgere:

27
1.6 Faktorer, der påvirker bredden af konfidensintervaller
Formlen igen: Bredden påvirkes af to faktorer: Tallet, der ganges med Standardfejlen

28
1.6.1 Tallet, der ganges med Afgøres af konfidensniveauet
Kan principielt fastsættes, som man vil Dvs. under vores kontrol Konventionelt 95% eller 99% Jo højere, jo større tal, og dermed jo bredere konfidensinterval Mao.: Jo mere sikker man vil være, jo flere værdier er mulige, og jo mindre præcist kan vi udtale os

29
1.6.2 Standardfejlen Formlen igen: To elementer heri:
Stikprøvens estimat af andelen i befolkningen n

30
1.6.2.1 Standardafvigelsen Populationsparameter kan ikke ændres
Estimeres fra stikprøven Formlen igen:

31
n Under vores kontrol! Da , kræver dobbelt præcision (dvs. halv bredde på intervallet = halvering af standardfejlen) 4-dobbelt n (for et givet konfidensniveau):
 4-dobbelt n (for et givet konfidensniveau):")
32
Eksemplet igen 4-dobling af antallet af respondenter i Vilstrup-målingen: 1148 4592 95% konfidensinterval for DF-andelen: Dvs. ca. et spænd på 0,018 (= halvdelen af første interval)
")
33
Usikkerhed på meningsmåling i Excel
Alle disse formler kan integreres i en Excel model. Denne er vedhæftet blokken og denne vil vi se nærmere på. opinionsmåling i Excel

Lignende præsentationer



>")















